- 开云体育中国官网入口 > 关于开云 >
开云体育·(KAIYUNSPORTS) 牛津、英伟达等提倡挂念压缩新范式: 老师时让模子学会断舍离
2026-06-15 03:11:42 66


裁剪|Panda
2026 岁首,各大 AI 厂商在崎岖文窗口长度上伸开浓烈角逐。Google 的 Gemini 3 Pro 已撑捏 100 万级 token 崎岖文,Meta 的 Llama 4 Scout 更宣称可解决 1000 万 token。GPT-5 系列也在快速鼓动长崎岖文材干。
按这个趋势,今天的大模子依然简略相连读完竣套《哈利・波特》,改日致使可能平直分析系数这个词大型代码仓库。
但数字背后也荫藏着一个要道问题:崎岖文越长,模子就越「记不住」。
这并非模子不够灵巧,而是 Transformer 架构自己的工程拘谨。当模子解决长文本时,需要为每个 token 保存 Key-Value(KV)状况,用于后续生成时的刺眼光谋划。这个缓存区域被称为 KV Cache。
KV Cache 的大小会随崎岖文长度线性增长:输入越长,占用的 GPU 显存越多,推理速率也越慢。关于百万 token 级别的输入,在大型模子和高精度推理场景下,KV Cache 的内存支拨可达到数十到数百 GB,远超单张顶级 GPU 的显存容量。
崎岖文窗口的竞赛,本色上是一场显存的战争。
靠近这一窘境,有筹划者们依然招引出多种「过后压缩」有筹划,也即是在模子老师完成之后,用各式算法对 KV 缓存进行精简。这些设施照实灵验,但它们都遗漏了一个更根柢的问题:若是模子在领先学习的技能,就莫得被指导去生成「容易被压缩」的里面默示,那么后期非论怎样压缩,恶果都将受到天花板限定。
就在这一配景下,来自牛津大学、以色列理工学院、AITHYRA 和英伟达的和谐有筹划团队提倡了一个新的念念路:与其过后弥补,不如老师时就让模子主动学会「压缩友好」的挂念样貌。

他们将这套设施定名为 KV-CAT(KV 压缩感知型老师,KV-Compression Aware Training)。

论文标题:Training Transformers for KV Cache Compressibility
论文地址:https://arxiv.org/abs/2605.05971
KV 缓存为若何此难压缩?
要集结这项有筹划的价值,先得弄了了一个直观上看似奇怪的事实:两个输出十足疏浚的模子,其 KV 缓存可能一个极易压缩,另一个根柢无法压缩。
这听起来很反直观。咱们经常合计,若是两个系统的「扫尾」疏浚,它们的里面过程应该莫得本色区别。但在神经网络全国里并非如斯。
有筹划团队用一个浅近的例子来证实这少量:「词频统计」。给模子输入一段笔墨,让它统计每个字母出现了几许次。这是一个只依赖「汇总信息」的任务,与每个字母出现的规则无关。
相似完成这个任务,不错有两种截然有异的里面杀青样貌。
第一种是「自说合词然」的杀青:模子对每个 token 进行孤立编码,临了通过刺眼光机制对一都 token 作念平均,得出统计扫尾。这种设施浅近平直,但存在一个致命颓势:任何对 KV 缓存的压缩都会冲突平均谋划,导致最终扫尾出错。有筹划团队从数学上评释了:这种杀青样貌,在表面上对任何进程的压缩都不具备容错材干。
第二种是「结构化」的杀青:模子在解决每个 token 时,非凡纪录序列的位置信息(即这段前缀有多长),当 KV 缓存被压缩成一个单一的向量时,模子不错诳骗位置信息对压缩后的汇总值进行重新校准,从而规复正确的统计扫尾。这种杀青样貌,表面上不错将任性长度的前缀压缩到仅剩一双 KV 向量,同期保捏零弱点。
两种杀青,疏浚的输出,截然有异的压缩性。
要道在于:圭臬的模子老师过程,十足莫得激发让模子去选拔第二种更结构化的杀青。因为在莫得压缩的场景下,两种样貌恶果十足一样,老师信号无从差别。
中枢设施
让模子在「戴着镣铐」的情况放学习
意志到这少量后,有筹划团队假想了 KV-CAT 老师有筹划。中枢念念路极为平直:若是你想让模子学会在 KV 缓存被压缩的情况下精深责任,就在老师时模拟这种压缩压力。
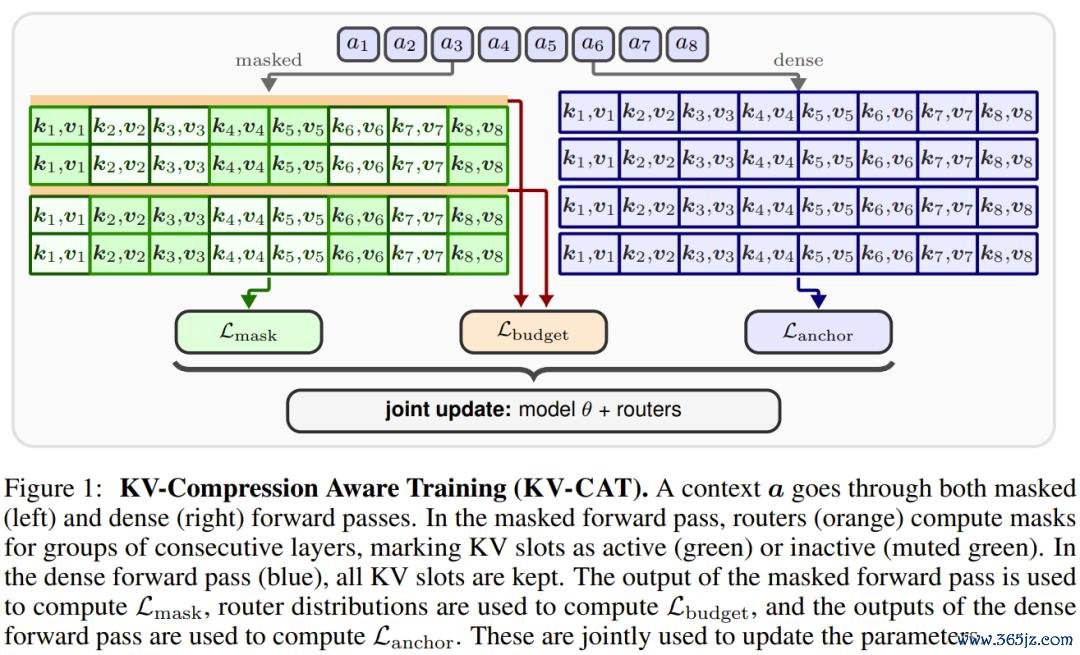
这近似于一种「挂念落魄老师」。平庸的模子老师就像让学生在考核时不错带着完竣的札记本作答 —— 虽然进展优异。而 KV-CAT 则是在老师时就充公大部分札记,开云中国逼着学生将最紧迫的信息内化成信得过的「集结」,而非对札记的依赖。
具体来说,KV-CAT 在原有的预老师模子基础上,引入了一组轻量级的「路由器」模块。这些路由器在老师的每一步会动态判断哪些 KV 槽位是必要的、哪些不错被屏蔽,筹划是保留约 50% 的 KV 缓存。每次前向传播,模子需要同期进行两次谋划:一次是精深的「全量」谋划(系数 KV 槽位都可见),一次是「压缩」谋划(仅保留路由器选中的 KV 槽位)。
老师筹划由三部分构成:
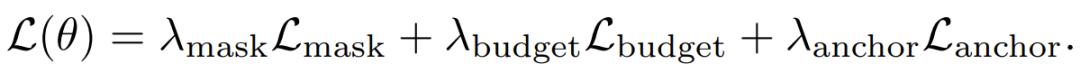
自蒸馏亏空,让压缩样子下的输出尽量靠拢全量样子下的输出;
锚定亏空,平直对全量样子施加圭臬的下一个词展望筹划,确保模子的基础材干不退化;
预算亏空,拘谨路由器实践保留的 KV 比例不偏离 50% 的筹划太多。
开云体育app2026世界杯中国官网下载系数这个词经过完成后,路由器模块在推理时会被关闭。输出的是一个圭臬的 Transformer 模子,它的参数与原模子疏浚,但其里面依然被老师成一种「自然压缩友好」的默示体式。后续不错搭配任性现成的 KV 压缩设施使用。
详确的数学刻画请探望原论文。
实验扫尾
全面朝上,且不以基础材干为代价
有筹划团队将 KV-CAT 应用于 Qwen2.5 的两个界限版块(0.5B 和 1.5B 参数),并在多个维度上对其进行评估。
首先,基础材干莫得亏空。 这是最要道的考据。在六个圭臬多选题基准测试上(包括 HellaSwag、WinoGrande、ARC 等),KV-CAT 老师后的模子与原始模子险些捏平:0.5B 版块平均擢升了 0.7 个百分点,1.5B 版块平均着落了 0.5 个百分点,均属于精深的老师波动范围。这证实 KV-CAT 莫得以就义通用材干为代价换取压缩性能。
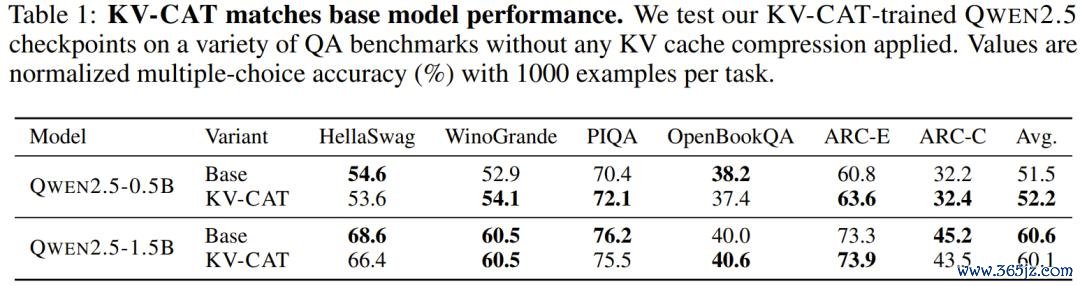
其次,后期 KV 压缩的恶果大幅改善。 在同等压缩预算下,与原始基础模子比较:
使用刺眼光匹配(Attention Matching)设施对前缀进行压缩后,续写文本的困惑度(perplexity)差距最多消弱了 3.21 倍 —— 也即是说,压缩后模子的进展与压缩前更为接近。
使用梯度优化法进行压缩时,KV-CAT 模子达到疏浚压缩质地所需的优化步数减少了最多 5 倍。这对实践部署至关紧迫:压缩自己也需要谋划资源,若是压缩速率更快,就意味着不错解决更多申请。
第三,「大海捞针」检索准确率显贵擢升。 有筹划团队假想了一个经典的长文检索测试:在一段充满搅扰项的长文本(约 1024 个 token)中藏入一个六位数的「密码」,然后将文本的 KV 缓存压缩后,测试模子能否正确回忆出这个密码。
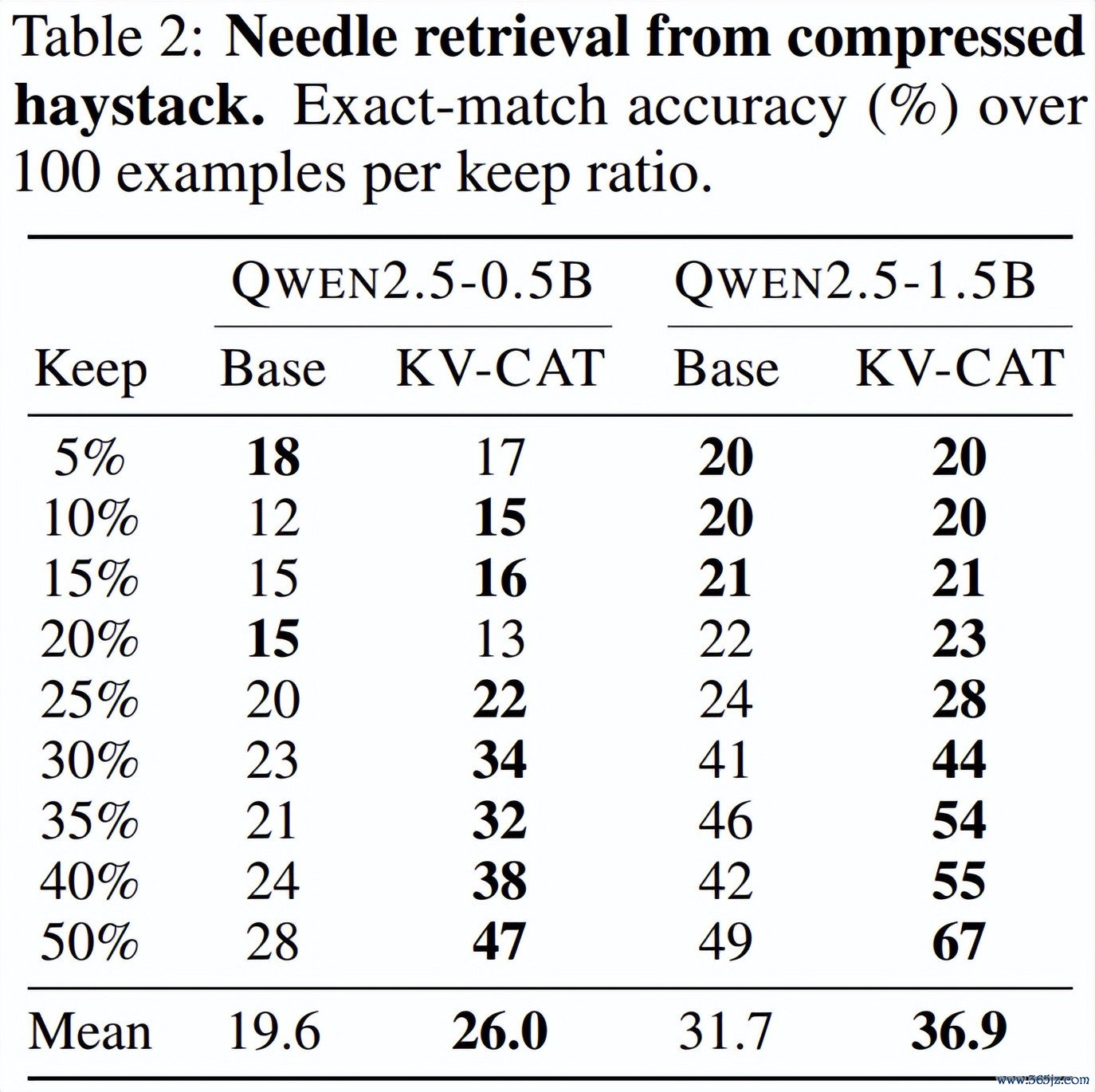
在保留 50% 的 KV 槽位的情况下,KV-CAT 版块的 Qwen2.5-0.5B 检索准确率从 28% 跃升至 47%,Qwen2.5-1.5B 则从 49% 擢升至 67%,擢升幅度接近 68%。即使在极点压缩(仅保留 10% 的 KV)的情况下,KV-CAT 版块的性能也与基础模子在轻度压缩时荒谬。
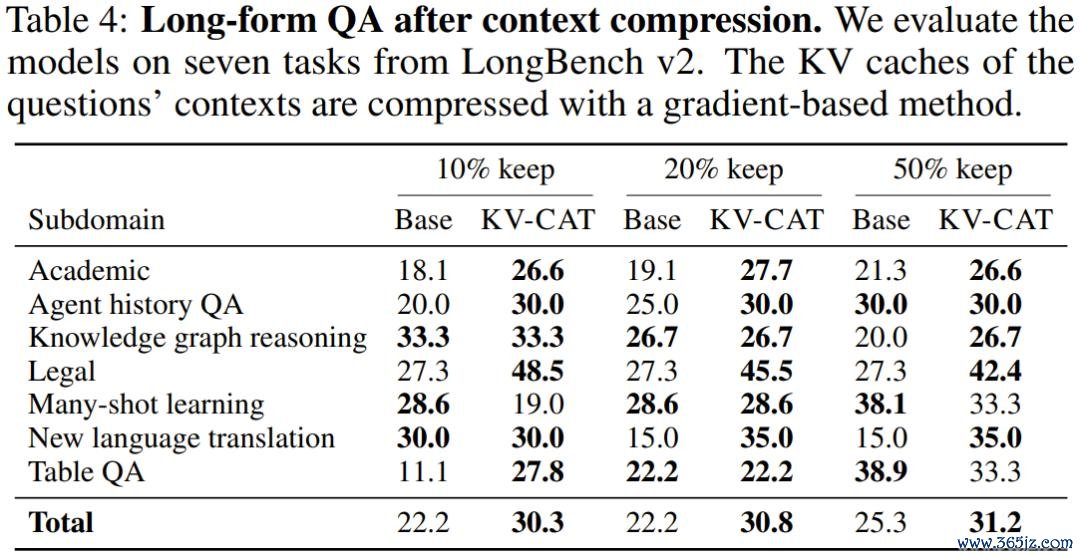
第四,长文问答任务也有明显改善。 在 LongBench v2 的七项长文本问答任务上,KV-CAT 模子在各压缩比例下的平均准确率均高于基础模子,最大擢升幅度达到 39%。
结语
KV-CAT 并不宣称要取代现存的压缩算法。有筹划团队明确指出,它的筹划是成为现存压缩设施的「底层增强」:相似的压缩算法,作用在 KV-CAT 老师过的模子上,恶果更好、速率更快。
这种「老师时为推理作念准备」的念念路,在 AI 系统工程领域并不生疏。但将其具体应用于 KV 缓存的可压缩性,并从表面上评释这种属性十足由模子的学习默示决定,是这项责任的中枢孝敬。
虽然,这套有筹划也有其代价:持续预老师引入了非凡的老师支拨,路由器模块加多了杀青复杂度,现在的实验界限也仅限于 0.5B 和 1.5B 两个相对袖珍的模子。有筹划者坦承,这套设施能否平滑推广到百亿致使千亿参数的大模子,仍是一个灵通问题。
但这一认识的逻辑是建造的。跟着崎岖文窗口的竞赛不断鼓动开云体育·(KAIYUNSPORTS),显存瓶颈正升级为制约 AI 系统界限化部署的中枢挑战。让模子从一驱动就「学会压缩」,而不是生成了难以压缩的默示之后再一火羊补牢,将是改日大模子老师工程中越来越值得可爱的假想维度。
关于开云
热点资讯
-
1.开云中国 英法律解说院裁定两名中国公民有罪,日后将宣判,酬酢
- 1

- 开云中国 英法律解说院裁定两名中国公民有罪,日后将宣判,酬酢
- 2026-05-09
- 1
-
2.开云体育中国官网入口 工业和信息化部批复第六代出动通讯系统技
- 2
- 开云体育中国官网入口 工业和信息化部批复第六代出动通讯系统技
- 2026-05-08
- 2
-
3.开云体育·(KAIYUNSPORTS) 他们把26载青春献给
- 3

- 开云体育·(KAIYUNSPORTS) 他们把26载青春献给
- 2026-06-12
- 3
-
4.开云体育中国官网入口 汉坦毒株被详情“东说念主传东说念主”后
- 4
- 开云体育中国官网入口 汉坦毒株被详情“东说念主传东说念主”后
- 2026-05-09
- 4
-
5.开云体育·(KAIYUNSPORTS) 浏阳烟花厂爆炸涉事企
- 5
- 开云体育·(KAIYUNSPORTS) 浏阳烟花厂爆炸涉事企
- 2026-05-09
- 5
-
6.开云体育·(KAIYUNSPORTS) 商榷团队把生物防伪“
- 6

- 开云体育·(KAIYUNSPORTS) 商榷团队把生物防伪“
- 2026-05-16
- 6
-
7.开云体育中国官网入口 南非球员: 我是来考英语四级的吗? 寰
- 7
- 开云体育中国官网入口 南非球员: 我是来考英语四级的吗? 寰
- 2026-06-13
- 7
-
8.开云中国 冒险新作《德瓦勒寓言》公布 小红帽探索童话后寰宇
- 8

- 开云中国 冒险新作《德瓦勒寓言》公布 小红帽探索童话后寰宇
- 2026-05-21
- 8
-
9.开云中国 福彩3D第2026144期曾诚恳和值跨度字谜
- 9

- 开云中国 福彩3D第2026144期曾诚恳和值跨度字谜
- 2026-06-03
- 9
-
10.开云体育·(KAIYUNSPORTS) 冠心病吃肉:3种肉刚
- 10

- 开云体育·(KAIYUNSPORTS) 冠心病吃肉:3种肉刚
- 2026-05-11
- 10
推荐资讯
-

开云体育·(KAIYUNSPORTS) 窘态!女子醉驾闯红灯
2026-05-22
-

开云体育中国官网入口 视频 | 豫篮联赛第八轮 103:76
2026-05-23
-

开云体育 梁靖崑在绝境中爆发 中国男队晋级世乒赛决赛
2026-05-10
-
开云体育·(KAIYUNSPORTS) 他们把26载青春献给
2026-06-12
-
开云中国 福彩3D第2026144期曾诚恳和值跨度字谜
2026-06-03